Dataset
Synthetic pizza dataset
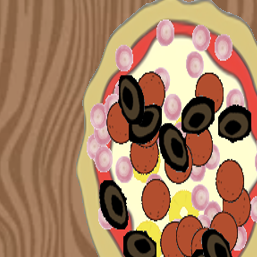
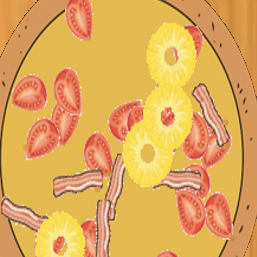
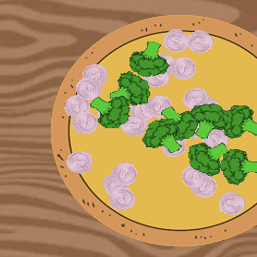
To evaluate our proposed pizzaGAN method, we created a synthetic pizza dataset with clip-art-stye pizza images. There are two main advantages of creating a dataset with synthetic pizzas.
First, it allows us to generate an arbitrarily large set of pizza examples with zero human annotation cost.
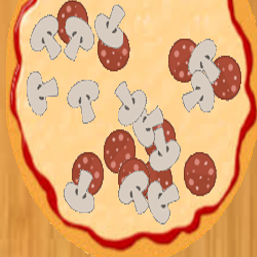
Second and more importantly, we have access to accurate ground-truth ordering information and multi-layer pixel segmentation of the toppings. Examples of the synthetic pizzas are shown below.
Together with the final created synthetic pizza images we used on the experiments of our paper (about 5500 images), we also provide the ground-truth segmentation masks for each topping, the ground-truth ordering of the toppings and the RGB images of all the intermediate steps of creating the final synthetic pizza. An synthetic pizza example is shown below:
Base pizza |
+ pepperoni |
+ mushrooms |
+ olives |
+ basil |
+ tomatoes |
+ bacon |
 |
 |
 |
 |
 |
 |
 |
Ground-truth
segmentation masks
per layer |
 |
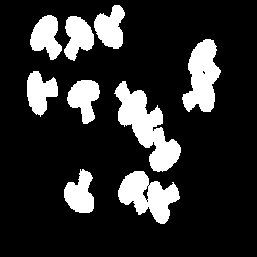 |
 |
 |
 |
 |
Real pizza dataset
Pizza is the most photographed food on Instagram with over 38 million posts using the hashtag
#pizza. We first downloaded half a million images from Instagram using several popular pizza-related hashtags. Then, we filter out the undesired images using a CNN-based classifier trained on a small set of manually labeled pizza/non-pizza images.
We crowd-source image-level labels for the pizza toppings on Amazon Mechanical Turk (AMT) for 9,213 pizza images. Given a pizza image, the annotators are instructed to label all the toppings that are visible on top of the pizza. To ensure high quality, every image is annotated by five different annotators, and the final image labels are obtained using majority vote.